最近,在一门涉及python的课上,老师讲解了Tushare这款股票数据接口。经过数据猿进一步探索之后发现,Tushare不但包含包含齐全的股票数据,还包含了其他领域的有用数据。除此之外,Baostock也是一个非常优秀的开源股票借口,使用起来更加稳定快速。
今天,数据猿就来尝试获取一下这两个接口的股票数据吧。
目录如下:

Baostock VS Tushare
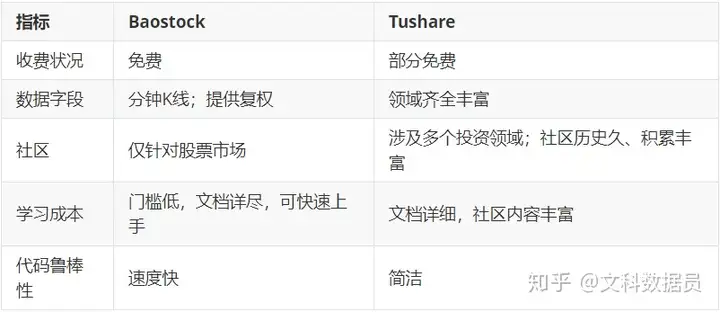
首先展示一下二者对比表,本来打算这个表作为文末的总结,但是由于数据猿毕竟门外汉,想写那么专业心有余而力不足,就先这个总结将放在这里的,文中不再赘述具体指标了。
Baostock
案例一:上证指数日交易量、振幅、换手率
第一步:导入baostock库,并登录
import baostock as bs
import pandas as pd
#### 登陆系统 ####
lg = bs.login()
# 显示登陆返回信息
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)第二步:接口配置
rs = bs.query_history_k_data("000001.SH", "date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,peTTM,pbMRQ,psTTM,pcfNcfTTM,isST",
start_date='2010-01-01', end_date='2019-12-31', frequency="d", adjustflag="3")
print('query_history_k_data respond error_code:'+rs.error_code)
print('query_history_k_data respond error_msg:'+rs.error_msg)补一个日线指标参数(包含停牌证券)
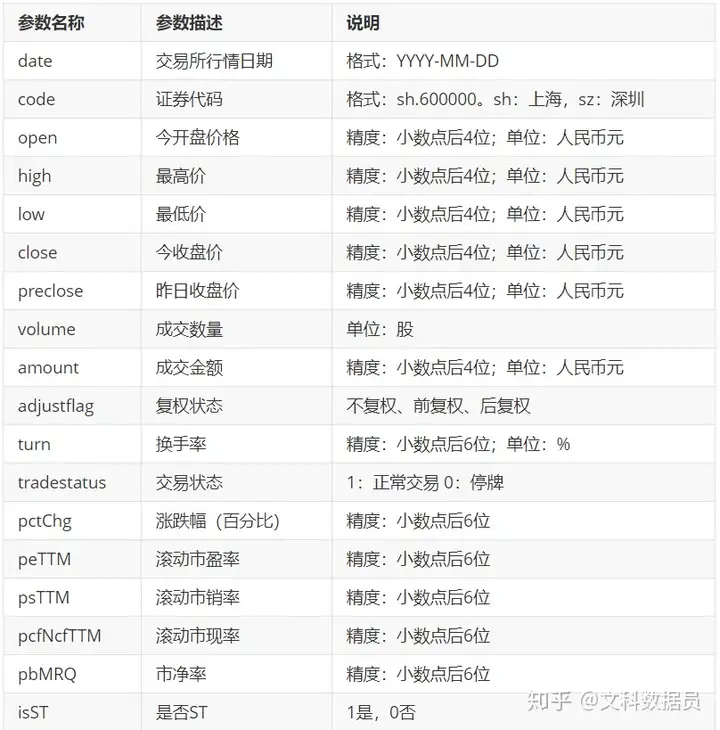
第三步:打印结果为pandas的Dataframe
#### 打印结果集 ####
data_list = []
while (rs.error_code == '0') & rs.next(): # 获取一条记录,将记录合并在一起
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
result示例
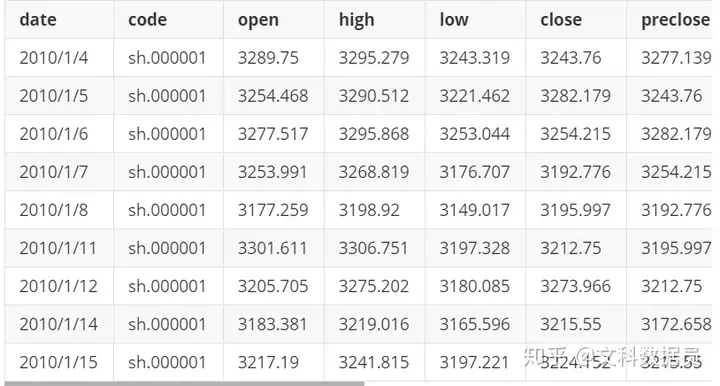
第四步:结果输出并存入CSV
#### 结果集输出到csv文件 ####
result.to_csv("D:\\history_A_stock_k_data.csv", index=False)
print(result)
#### 登出系统 ####
bs.logout()Tushare
案例二:南方传媒和浙江传媒股票对比
第一步,导入Tushare等相关库
import tushare as ts
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
import warnings
warnings.filterwarnings("ignore")第二步,接口配置
#股票代码、起止日期可替换
caixin = ts.get_hist_data('600633', start='2017-07-01', end='2020-05-08')
caixin
nanfang = ts.get_hist_data('601900',start='2017-07-01', end='2020-05-08')
nanfang第三步,二者收盘价
收盘价形成新的Dataframe
#收盘价close
data = {'浙江传媒财新': caixin.close, '南方传媒':nanfang.close}
df = pd.DataFrame(data)
df排序
#排序
df.sort_values(by='date',ascending=True,inplace=True)
df第四步,可视化
收盘价可视化
#pandas支持matplotlib的,直接使用df.plot(kind='line')画折线图
import matplotlib.pyplot as plt
%matplotlib inline
df.plot(kind='line')
plt.xticks(rotation = '45')
plt.show()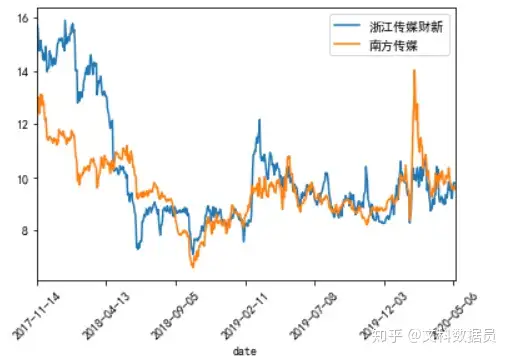
单支股票股价集中度可视化
# 股价集中趋势可视化
import seaborn as sns
df.round(0)
plt.style.use('ggplot')
df['浙江传媒财新'].plot(kind='hist',bins=30,normed = True)
df['浙江传媒财新'].plot(kind='kde')
plt.show()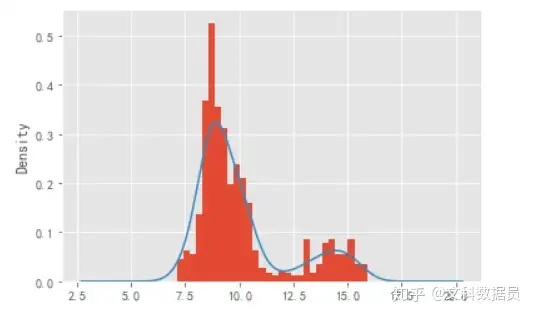
单只股票股价拟合可视化
df_pre_caixin = df['浙江传媒财新']
pre_caixin = pd.DataFrame(df_pre_caixin)
pre_caixin['MA5'] = df_pre_caixin.rolling(5).mean()
pre_caixin['MA20'] = df_pre_caixin.rolling(20).mean()
pre_caixin['MA60'] = df_pre_caixin.rolling(60).mean()
pre_caixin.plot()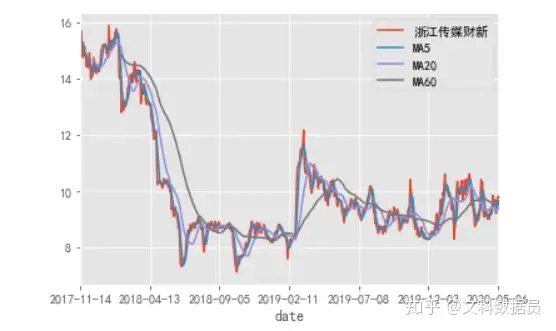
小结:
二者各有千秋,适合自己需求的才是最好的;
数据猿是门外汉,可能表述上多有错误,还请经管类的朋友多多指导!
BTW,有意交流的,可以在公众号后台回复0,数据猿拉你进群!
参考资料:
Tushare官方文档:https://tushare.pro/document/2
Baostock官方文档:http://baostock.com/baostock/index.php
往期精品:
参考资料:
个人博客「源来是这样」
https://www.cnblogs.com/readiay/p/12846944.html
文字编辑:数据猿Riggle
文章来源 于 公众号:文科数据员
https://zhuanlan.zhihu.com/p/143118272
发布于 2020-05-23 22:37
tushare
Python 开发
Python
写下你的评论…
16 条评论
默认
最新
主要是很多人不会Python,获取数据还是不方便
2021-01-26



![[捂脸]](https://pic1.zhimg.com/v2-b62e608e405aeb33cd52830218f561ea.png)



发表回复